
Take pride in your eBook formatting (Part VI)
This is the sixth installment of a series of articles. To read the previous one, please click here
Time for the clean-up of your manuscript
Now that we’ve exhaustively covered the preliminaries, it is finally time to put it all to work for us and begin creating an actual eBook source file. I know you’ve been waiting for this with held breath, so let’s just roll.
The first thing we need is a cleaned up text version of your manuscript. By that, I mean a version that has proper curly quotes, correct dashes, including em dashes, ellipses and so forth.
I can’t even count how many times I have read on message boards, not to use curly quotes, ellipses etc. and I cannot stress how misguided those recommendations are. They usually stem from people not properly understanding the workings of eBook creation and going for a cop-out instead of trying to really address the problems they might have encountered. Bad advice! I will show you how to do it right because publishing a book without proper typographical characters is like writing text without ever using the letter ‘e’.
The way I clean up my text is usually by loading it into a word processor and doing a series of search and replaces. The first one is replacing all occurrences of " with ". Yes, this is no typo, I am really replacing all quotes with an identical quote. By doing this I am putting the word processor’s logic to work. By replacing all quotes in the text with themselves, the program automatically smart quotes them, creating the correct, corresponding curly quotes for me throughout the text. Now that was cool, wasn’t it?
Next step, we do the same thing with single quotes, by replacing all occurrences of ' with '. Again the software will make sure to use the typographically correct curled single quotes in all instances.
Next up, em dashes. I have a habit to mark em dashes by writing two regular dashes in my text, so a quick search that replaces -- with — does the trick for me in no time.
The last step are usually ellipses, in which a search and replace of all occurrences of ... with … will automatically create proper ellipses for me. This is important because it allows the eBook reader to do proper line breaks after the ellipses, whereas three individual periods can easily confuse the device and render the first period on one line and the remaining two on the next — which is a serious typographical flaw. In addition, ellipses are spaced correctly for each font for best readability, and are part of the typographic vocabulary for a reason, so don’t just ignore them.
If you have a word processor that allows you to search for text styles — some do, others don’t — you can now do a search and replace that will save you considerable time down the line. Try to find all instances of italic text and wrap them with <i> tags now. Using wild cards, you can pretty much automate this process and save yourself hours of manual work with just a few mouse clicks here. In Word, for example, go to the search box and hit Ctrl-i to select italic, and in the replace box enter <i>^&</i> and then hit Replace All and you should be all set.
Do not fall for the temptation to do the same thing with your bold text, however, such as your chapter headings! We will tackle those differently a little later on.
We now have a clean text file. Select the entire text now and copy it to your clipboard. We are leaving the word processor and enter the domain of HTML.
Nice, clean and predictable in HTML
Open your programming editor (See Part III of the series for a quick discussion of programming editors), create a new file and paste your text into it. You will notice that all formatting is lost, and that is just as well. In fact, that is what we want. It is probably the most important step of the entire process, to get rid of the unpredictable word processor formatting. We will now begin to massage our text back to shape with a few, elegantly applied steps.
Once you got over the shock that all formatting is lost, you may also notice that every paragraph of your original text is now in one single, long line. (If that is not the case, you should adjust the line width of the editor to its maximal possible length through the Options settings.)
We will use this fact to our advantage and wrap every single line with a paragraph tag. This can be easily done using a regular expression search and replace. Regular expressions are extremely cryptic and I do not expect you to understand how they work, so just follow the next few instructions, if you may.
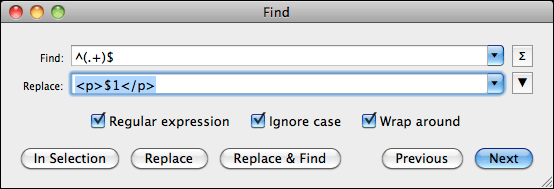
Open the search and replace window in your editor and make sure Regular Expressions are enabled. Occasionally you may find a checkbox in the search window, so give it a quick look. Now enter ^(.+)$ as the search term. Then enter <p>$1</p> in the replacement line. Run the search and replace across the entire text and take a look at your results. Every line of text should now be wrapped neatly by an opening <p> and a closing </p> tag. If they are not, your editor might use a slightly different syntax. Undo whatever the editor just did and enter <p>\1</p> in the replacement line instead of the previously used enter <p>$1</p> replacement term. Run the replacement and check the results. If it is still not correct, your editor might not support regular expressions.
In theory you could do these replacements in your word processor also, though quite honestly, I don’t really trust them that well, and personally prefer the use of a programming editor instead, which is also significantly faster.
Dealing with special characters the right way
The next step for us to do is to replace all special characters with their proper HTML entities. I’ve seen a lot of discussion about this, and how it’s not working right or is platform dependent, but trust me, when I say, that it is all bologna. There is a very safe way to handle this in HTML that will properly display on every HTML device, regardless of font or text encoding. The key to success lies in HTML’s named entities.
If we take the ellipses (…), for example, in HTML there is a special code that tells the device to draw that particular character. It is called … With this entity, the device knows to draw an ellipse that cannot be broken into parts and is treated as a single character.
If you use the entity — the device will render a proper em dash. Proper length, proper size and all.
Next up are quotes. For that purpose, HTML offers “ and ” , entities that represent curly left and right double quotes, just the way we love them. Correspondingly, ‘ and ’ are the entities to draw curly single quotes.
And as easy as that, we have circumnavigated all compatibility issues for special characters. These named entities will always be rendered correctly, unlike the cryptic numeric entities that some people are using.
If you happen to see something like this in your HTML code – ¯ – you know you’re asking for trouble, so make sure to use named entities only!
There are, of course many more, including entities for currency symbols, accented characters etc. and there are two basic ways to go about having them all replaced.
The brute force approach would be to search and replace all of them by hand, one entity at a time. This is not only time consuming but also prone to error, as you could all too easily overlook some in your text — but it may be the only option available to you.
The second — and easier way — is to automate the process. TextMate, the programming editor I am using, has a function called “Convert Selection to Entities excluding Tags” and it does exactly what we need. With it, it takes me one mouse-click to have all special characters in my entire book converted to named entities. Remember, using the right tools for the job will always make your life easier!
Alternatively, there are a few websites on the Internet that allow you to paste in your text and it will convert it for you, such as http://word2cleanhtml.com. However, I take no responsibility for the quality of the conversion and I want to point out that you are inserting your entire book into a website you are not familiar with, where it could — theoretically — be stored and re-distributed. I’m usually not paranoid but it is something I thought I should point out.
If you have not been able to wrap all your italic text instances with <i> tags in your word processor, now would be the time to do that — by hand. It may be a bit tedious, as you will have to look for every instance of italic text in your manuscript and manually wrap it with the tags, but I found that usually their number are limited and it doesn’t take too long to do.
Once we are done with all that, we have a very basic HTML source file for our eBook — one that is guaranteed without strange formatting errors and things that plague countless eBooks. Make sure you save this file somewhere, using an .html file extension. This will later allow us to quickly evaluate and check the eBook file in an ordinary web browser. In fact, if you double-click the file, you should already be able to take a look at it in your browser. Paragraphs should be nicely separated and italic text should show as such.
As you can see we’re quickly getting there now, but, of course, we are not done yet. In the next installment we will begin to fine-tune the various elements of the book and give it the polish it deserves.
Part I • Part II • Part III • Part IV • Part V • Part VI • Part VII • Part VIII • Part IX
 If you want to keep up with my eBook formatting work, don’t forget to subscribe to my Newsletter. That way I can keep you updated about the latest developments, updates to my books, code snippets, techniques and formatting tips.
If you want to keep up with my eBook formatting work, don’t forget to subscribe to my Newsletter. That way I can keep you updated about the latest developments, updates to my books, code snippets, techniques and formatting tips.
Also, don’t forget to check out my book Zen of eBook Formatting that is filled with tips, techniques and valuable information about the eBook formatting process.
Your “Take pride in your eBook formatting” series has been excellent, Guido. You’ve written ir so that even someone with limited computer knowledge could follow your instructions.
Thank you very much for the compliments, Vicki. Much obliged.
I happened to run into David Burton in a web forum and he kindly turned me to your blog series. It’s been a great read, highly informative and immediately useful. Thanks!
I am glad that you find the series helpful and hope you’ll be able to apply some of it for your own work.
Regarding the entity codes, I happen to have some pinyin (Chinese phonetics) which uses characters in the Latin-B unicode group which don’t seem to have entity codes (ie: Nǐ hǎo). Will I really have a problem if I just use the numeric unicode for these?
I have to admit that I have no experience with Chinese phonetics and am not sure how standardized their Unicode implementation is. I would expect it to be fairly safe to use numeric entities in that case but I would definitely double check on a few platforms and load it on a Kindle, a PC, an iPhone, a Mac etc just to make sure.
Guido, is there a fast way to replace all left and right quotes in jedit? Does it have something similar to the textmate you use?
If you mean replacing regular quotes to turn them into curly quotes, I don’t think any programming editor can do that. It requires some logic to identify the opening and closing quotes as they require different replacements. Word processors usually have that logic when “smart quotes” are turned on, but not programming editors.
If you mean by replacing, replacing the curly quotes with their respective entity values, you can do that in a quick two-step search and replace. Simply search and replace all occurrences of “ with the entity &ldquot; and then replacing all occurrences of ” with the entity &rdquot;
I’m trying to follow the formatting steps, and everything goes perfectly except that I can’t make jedit actually find the curly quotes to replace them with the entity values. I set it to find, and it claims there’s none in the document, even though I can clearly see there are. Am I missing something obvious, or am I doomed to have to replace every one of my 3600 instances of various curly quotes by hand?
Thanks if you have any ideas. And if not, thanks anyway, this is a really awesome step by step guide all the same. And way faster than I thought it would be.
Jason,
The best way is to highlight one of the curly quotes in your text and copying it to the clipboard. Then paste it from the clipboard straight into the search box. That way you’re making sure you have exactly the same code there as in the text.
I hope this will help.
Dreamweaver proved tricky on getting the paragraph tags properly rendered; I wasn’t able to use either of your above examples, but here’s what did work if anyone’s interested: FIND: REPLACE WITH:
Note-I did highlight specific text when doing this and used Source/Code view. If I’d done the cntl+A option (which I normally would have) & done the find/replace, there would have been an extraneous hanging tag or two.
Guido – thank you! This is fantastic info & explanations. 🙂
Oops! Something didn’t like those Find/Replace codes. Here they are posted as a jpg on my site:
http://www.larissalyons.com/images/para_fix.jpg
Looks good to me. What exactly is happening? Feel free to send me the file if you wish.
Guido, thanks for this excellent series. I’m taking a crack at converting my novel myself thanks to your encouragement, but I have a question. My novel includes a second style of paragraphing designed to mimic an online chatroom format–a different font, bold screen name and a colon followed by tabbed, regular font text. Do you have a suggestion for formatting this either in Word or the text editor? Is there an opportunity to make this even more distinctive in e-book format by inserting the chat dialogue in a box?
Thanks for your thoughts!
Larry
Larry, this is fairly easy to do. All you have to do is create a separate paragraph style for this, say, you call it “chat.” Then you wrap all the text with the corresponding tags, like this
<p class=”chat”>Here is where your text goes</p>
The key is now to modify the “chat” style so that it uses a Courier font-family, maybe adds a margin to indent the text and sets a border to visually frame the entire block with a thin line.
Hi Guido
Thanks for this guide. It was indispensable in publishing my first ebook, but I’m having problems now with my second. The ‘replace italics’ instruction is no longer working in Word.
I’m doing exactly what I did before but it’s now placing the italic anchors AFTER each italicised word or phrase and not wrapping around.
I’ve no idea why it would do this. Is it a problem you’ve encountered before?
Appreciate your help.
Cheers
Andy
I have not seen this problem before, but sometimes italic conversions do not work properly, when there is an italic font in use instead of the italic font setting. I had this in a client’s book just this week where she used “Courier New Italic” in her manuscript, instead of “Courier New” and then making it italic.
I had to adjust my search and replace accordingly to locate and wrap those instances. You might want to take a closer look at your own italic instances and see if there is something wonky there.
Thanks for the response. It’s not that, though. I’m using (Default) Arial and I’ve checked formatting against the previous document that converted correctly and there’s no difference. It’s a puzzler. Looks like I’ll have to do them manually once I’ve put the novel into Dreamweaver.
Is there a problem if the anchor uses ’em’ and not ‘i’ – ’em’ seems to be the default for italics in Dreamweaver.
“By replacing all quotes in the text with itself, the program automatically smart quotes them”
This only works if you activate “replace straight quotes for curly quotes” (I’m paraphrasing here because I’ve got a different language version of Word) in Word (it’s on the auto-format tab in the dialog box that pops up if you choose Extra -> Auto Correct from the menu).
Guido, you are a complete stud. Flat out. Thank you for this information and I wanted to help by making a tweak for any of your readers who might use Open Office instead of MSW:
If you use <i>^&</i> to replace the italics, you’ll find the ^ in your final results. So when you find and replace in OO, just type <i>&</i> and it will turn out perfect.
My two cents back to you kind sir, as a thank you.
Jaime Buckley =)
Blast. You see how important it is to code things right?
Let’s try that again…
If you use “<i>^&</i>” to replace the italics, you’ll find the “^” in your final results. So when you find and replace in OO, just type “<i>&</i>” and it will turn out perfect.
Hmmmm.
Ok Guido—you’ll have to fix the code so it actually shows up…lol.
I tried to help anyway. (smirk)
Yeah, it is a little tricky to post HTML tags without them being interpreted.
First of all, your guide has been very helpful in formatting my first e-book. And besides, it’s always nice to meet a fellow John Sinclair fan.
However, I have a specific problem. I use the German edition of Word, so whenever I use curly quotes, they appear in the common German layout, first lower quotes and then upper quotes. This is a pain in the backside, if you primarily write in English, so I always switch off the curly quotes first thing when I get a new computer. I switched them back on when preparing my text for e-book formatting. But when I did search and replace, I got the bloody lower and upper curly quotes again. Setting the document language to English doesn’t help either, I keep getting lower and upper quotes.
Do you know a way to work around this? Or is it best just to keep the straight quotes, even if it’s not as pretty. Because German quote format in an English language e-book would probably cause more confusion than plain straight quotes.
I would have expected that switching the document language to English would fix the problem but since it is a Microsoft product I am not surprised that it doesn’t do. Nothing Microsoft does works the way it should.
Here’s what I would do. Leave the quotes as they are in German. Then convert them to named entities the way I described. After that I would manually search and replace all occurrences of “ with something like &dummy;
Then I’d replace all occurrences of ” with “ and finally replace all occurrences of &dummy; with ”
You have now effectively exchanged the two symbols with each other. It takes a few extra steps but fixes your problem.
Thanks for the help. Your comment about the inefficiency of Microsoft products, which I completely agree with BTW, actually gave me another idea. I imported the text into my old Lotus Word Pro program, did the search and replace and with Lotus, changing the document language actually works. But then it’s not a Microsoft product.
Thanks anyway and also thanks again for this extremely helpful guide.
That’s not a bad idea, really. Glad that worked out for you.
I think I’m in love with you.
Seriously.
Okay, got that out of my system. Now, when I write in Word, I utilize “page breaks” between chapters. Will this cause a problem during the rest of my conversion process? Is there any specific way I should format my chapters to help the conversion?
Thank you, Heather. The page breaks do not interfere with the process. When transferring your text from the word processor to the text editor, these page breaks will be lost, but you will re-introduce them later through the chapter headings and the “chapter” style.
Hey Guido. Much thanks for the guide. I couldn’t get &rsquot; [right single quote] to work, so I used ' [apostrophe] instead. Is that a good idea?
Nevermind…I figured it out.
It is ’ – was that your mistake?
Excellent series, Guido. I’ve been pushing these links on the social media sites I frequent.
I think I’m going to re-read this series once a week until I’m ready to put my ebook together. 🙂
One question: Forgive me if I’ve missed something, but why do we need to do the find-and-replace in Word first and then again in the HTML editor? Does pasting it into the editor wipe out all those changes made in Word?
When I type in Word it automatically converts double dashes into em dashes and three periods into ellipses once you add a space after the word that follows them. I have to manipulate my quotes a little, though, because if you have a character break off in the middle of speaking with an em dash, Word uses an opening quote instead of a closing quote – wrong direction. My solution is to type a random letter between the em dash and the quote, then go back and take it out. Same thing with using single quotes to denote part of a word left out, such as ’tis or ’em – Word puts it in the wrong direction and I have to change it.
That is to say, puts it in the wrong direction like this blogging software just did on my second example. 🙂
Hi Guido,
I’m a bit lost about how to do a mass replacements italicized and/or bolded words search and replace in a word processor. Is this what you suggested or am I lost about that too?
Specifically which word processors can do that? I use Atlantis and Word mostly.
Thanks.
I am not familiar with Atlantis but Word can most definitely do it.
Thanks,
But how do I do it in Word, and which version please. I know how to search for specific words or phrases. Can I search and replace for ALL italicized words in a single go?
I’m not sure if I’m getting this.
Hi Guido
I’m confused with the &hellip, &mdash, etc. How does this look in the copy? I can’t get the jEdit search and replace to see the quotes, …, etc. I did have the “replace with smart quotes” checked in Word — what I supposed to?
It’s such a confusing subject for first-timers, but I’m just step-by-stepping it with you. Thanks!
Ok, this is getting embarrassing, but I don’t know how to do the following. Can you really dummy it down for me, because when I copy it in the text and try to paste it in the “find” box in jEdit, nothing happens. Also, I still don’t get how to open my .html file in my web browser. Sorry to be so clueless!
Alisa
“The best way is to highlight one of the curly quotes in your text and copying it to the clipboard. Then paste it from the clipboard straight into the search box. That way you’re making sure you have exactly the same code there as in the text.”
The named entities work like this. Let’s assume you have an ellipse in your text and it looks like this.
this is a test…In your HTML source you would have to replace the ellipse with a named entity so it reads like this
this is a test…When this HTML file is being displayed in a browser or eBook reader it will then correctly the … named entity as the “…” symbol.
To open your HTML file in a web browser, all you really have to do is to double-click it. It will then automatically be displayed in your default web browser, usually.
Why your search doesn’t work, I am not entirely sure. But if you want me to I can take a look real quick. Send me your HTML file by email and I’ll take a quick look.
Oh, oh, I got the ellipses, etc. fixed! I had to highlight it in the copy in jEdit and then open the find box, and it would be in the find box.
Where would I be when I double-click on the html file? That’s my confusion. Am I in Word? On the internet? Sorry to be so dumb!
You are in no application when you double-click the file. Locate the HTML file with File Explorer when you’re in Windows or with the Finder on a Mac. Once you have found the file, simply double-click it.
Okay, got it, thanks so much. You are so patient, I’m hoping you can help again — my quotes, etc., aren’t coming up (the codes are showing in the nook file). What am I doing wrong? Here’s what I have at the beginning:
html, body, div, h1, h2, h3, h4, h5, h6, ul, ol, dl, li, dt, dd, p, pre, table, th, td, tr { margin: 0; padding: 0.1em; }
p
{
text-indent: 1.5em;
margin-bottom: 0.2em;
}
p.chapter
{
text-indent: 1.5em;
font-weight: bold;
font-size: 2em;
page-break-before: always;
margin-top:5em;
margin-bottom:2em;
}
p.centered
{
text-indent: 0em;
text-align: center;
}
span.centered
{
text-indent: 0em;
text-align: center;
}
CHAPTER 1
blah blah blah &mdash I
Oh, Lord, I forgot the codes would change here. In front of “Chapter 1” it says
(open carrot)p class=”chapter”(close carrot)(open carrot)p class=”centered”(close carrot)(open carrot)span class=”centered”(close carrot)CHAPTER 1(open carrot)/span(close carrot)(open carrot)/p(close carrot)
(open carrot)p(close carrot)
I swear I’m not normally this dumb.
You are missing a semicolon after the mdash entity. You need to write — for it to work. All entities start with the & sign and end with a semicolon.
You are officially my favorite person, Guido! Thanks so much for all of this!
Guido,
Having trouble with this seemingly simple step in your penultimate paragraph: “Make sure you save this file somewhere, using an .html file extension.” I went from Word to jEdit, supplanting the former’s formatting with HTML tags successfully, but can’t seem to find a “Save As…” or “Export…” function which allows me to give the final product an .html extension. What am I overlooking.
And, in any event, thank you for this practical and generous resource.
Dan
All you have to do is select “Save as” – which I am sure jEdit has – and then type in a file name that ends with .html, such as test.html
I figured it was something absurdly simple.
Thanks immensely,
Dan
Hey, we all can’t see the forest for all the trees sometimes. 🙂
The second — and easier way — is to automate the process. TextMate, the programming editor I am using, has a function called “Convert Selection to Entities excluding Tags”
This sounds great but how do I access it? I am using Textmate and cannot find the function.
From the menu bar, go to “Bundles->HTML->Entities”
Finally you get to the subject of your series! You are the Tristram Shandy of Kindle formatting writers.
BBEdit also has a lot of pre-built regex functions that help in doing these tasks (under the Text and Markup menus), as well as standard grep/regex, and you can sequence these up in “text factories” that you can use over and over on different documents.
Admittedly rare, but cases like ’tis (a contraction of it is) will not be caught by most smart quotes filters.
You can catch it by a white space plus dumb apostrophe search and just manually inspect each instance, or build up your own list of such exceptions and build them into your regex sequence. Use
\s’ or [:space:]’
… depending on your regex engine.
Personally I prefer to use use search and replace to put tags on titles and links and the like (e.g., for headings and chapter starts) before doing entity encoding, because in rare circumstances an entity-converted character can screw up a search for whatever you’re using as the hook for your searches. The BBEdit HTML-to-entity filter has an option to ignore angle brackets, so it can be applies post HTML tagging.
Hi Guido,
This is such a wonderful de-mystifying blog. Thank you.
Can you say a bit more about fonts, and how hard it might be to use a different font for the main text of an ebook? Calibri is soooo…well, plain. I get how an image could be used for chapter heading fonts, etc., but I’m wondering if you can explain what’s up with the limitations on the main body of the text, and what can be done about it, if anything.
Thanks!
Steve
Font options are virtually non-existent at this time. This will change with future readers, perhaps, where yo uwll have the possibility to actually include font data in your eBooks, but for now you are limited to the three very basics of HTML.
Using the font-family setting in your styles, you can select either a “serif”, “sans-serif” or “monospace” typeface. That is all. Using any particular font names is prone to causing problems because not all readers have the same font implementations. Therefore it is best to stick to the generic types that I mentioned.
Hello Guido,
Not sure if I am being dumb here but when I view the document in a browser (Firefox and Safari) I am getting apostrophes showing up like this: they’re
Quotes also show up in the browser like this: â€
They look fine in TextMate, but when viewed as an HTML file they mess up. Should I be concerned?
Thanks,
UPDATE:
Guido,
I was getting ahead of myself.
Upon finishing your instructions re Calibre all is well and looking good.
Apologies for the premature question and thanks for the great article.
All best,
Still, make sure you are properly converting the special characters to named entities. Otherwise, even though it may look good on your end after Calibre went over it, it may look just as broken as before on certain devices.
Named entities are a MUST for solid eBooks.
Hi Guido,
thanks for this guide.
I am preparing a file for the first time ever, and it is all easy to follow and goes smoothly. (So far. Knocking on wood)
Only thing is that I am actually writing in German and need the named entities for the lower and upper curly quotes. 🙂
I googled for it but I do not trust myself choosing correctly …
Thanks for your help,
The Umlauts are named as such
ä ö ü Ä Ö and Ü
For more info, here is a reference overview – http://www.w3schools.com/tags/ref_entities.asp
Thanks Guido
And you say TextMate would do this all on one go?
Next stop: http://macromates.com
Yes, TextMate does take care of those conversions with one button press.
Has anyone tried using Notepad++ for the HTML tweaking? This is the software I’m working with, as jEdit stoutly refuses to be installed onto my laptop, and I can’t convince the Replace function to put the and where they belong. I used the search and replace codes that Mr. Henkel suggested. They didn’t work.
Has anyone had this problem?
Yes, Notepad++ works fine and can do regular expression search and replaces just fine, I believe. The key is to turn it on in the search dialog box. Maybe this page will help a little.
http://markantoniou.blogspot.com/2008/06/notepad-how-to-use-regular-expressions.html
Thanks for the link! And thanks for this series, by the way.
Brilliant blog, Guido!
Do you know if “Convert Selection to Entities excluding Tags” is available on E Text? For those of us without a Mac it would be enormously useful.
JJ
I’m sorry I do not know. I don’t even know what E Text is, to be honest.
Hey Guido I think I am messing up here, I tried the find replace thing but I still get things like these “Copyright © ” “How I’ll Know” and ” “I Love You— and no I am not saying I love you its cut and paste from what I am seeing. 😛 basically the single quotes, double quote marks and the like are vanishing when I check the txt file in my browser. So is this me being thick or something? please help me with this. I am using a mac puter, pages word processor copy pasting from pages into Textmate if that helps at all who and I did follow the steps of replacing the things but it don’t seem to work. so a step by step dummies version perhaps? yours with much appreciation.
Rin
P.s. this blog rocks as do you sir!
It would appear you are not converting those special characters to named entities, as described in part six of my tutorial – http://guidohenkel.com/2011/01/take-pride-in-your-ebook-formatting-part-vi/
I must be doing it wrong then because I did what you said, the find and replace thing, several times over. 🙁 each new attempt seems to bring the same result. I must be doing something wrong. Thank you for quick response am going to keep trying.
Tarin, feel free to email me the HTML file real quick and Ill take a look.
hey Guido, it’s ok, when I put it into Calibre everything was normal again, I guess I must have done something right afterwards when I redid it all over from scratch. But now am having issues centering stuffs but I am determined to figure out what am messing up now. I must learn 😛
Thank you Guido you totally rock!
Thank you so much for this series. I am always trying to improve the look of my eBooks and those of my friends. You write in such a clear and concise way that I feel sure I’ll be able to apply what I’ve learned. (If not I’ll be back to cry on your shoulder.)
Guido, thanks for the guide. On copying the text from MS Word to JEdit, I found all the text appeared on one line. It seemed like your post above indicated it would be one line per paragraph, not one line for the entire manuscript.
Did I misunderstand?
Everything on one line makes it a little harder to work with.
Yes, something is wrong then. It would appear as if Word has inserted only soft line breaks. You should search and replace all of those with hard line breaks. Once you’ve done that, the text show up in one line per paragraph in the editor.
Thanks, Guido. Can you explain how to do that in Word? (I’m using Word 2008 for Mac, if it matters.)
Actually, after googling it, I tried the replacement, and that doesn’t seem to be the issue. It’s all paragraph breaks, already. Does JEdit require any kind of configuration?
I broke down and got TextMate. It’s working properly in that, so I assume it’s something that I needed to configure in JEdit, not in MS Word.
Glad you got it to work. I don’t use JEdit, so I’m not really familiar with its behavior or settings.
Thank you for the guide…extremely clear and time saving. I wanted to post here in case there are still questions about how to do “Convert Selections to entities” for Notepad++ users. There is a plugin for Notepad++ called HTML Tag. It is available through the plugins menu on Notepad++: select plugins>plugin manager, select HTML Tag from the list and install. Once you have it you can “Select All” of your text. Then plugins>HTML Tag>Encode HTML Entities. This will change your special characters to the HTML codes Guido discusses (for example, “…” to “…”).
It is best to do this before you add the paragraph tag because doing so after will change the characters “” into there corresponding HTML code, like this: “<p>” and “</p>”. But, if you have already added the paragraph codes when you run “Encode HTML Entities,” don’t worry. Just do “Find and replace” with find=<p> and replace=<p>. Then find=</p> and replace=</p>. Then your paragraph tags are back!
Hopes this helps anyone still seeking this solution.
Cheers
Hi Guido,
This is a fantastic guide! I’m almost done formatting my ebook and think I’ve gotten most of it. Using TextWrangler.
Here’s my question: do I need to use an html entity for a hyphenated word? Also, do you happen to know with words like ’tis or ‘cuz, which way that single quote should face?
Thanks so much!
Joanne
Joanne, you will not need special entities for standard hyphens, so don’t worry about hyphenated words.
As for the single quotes in words like ‘cuz, it is my understanding that you should use left single-quotes. Every time you have an omission at the front of the words, the left single-quote is used. In all other cases, the right single-quote is being used.
However, it is a rule that very few people actually adhere to these days, and even most word processors are not smart enough to follow the rule, using right single-quotes in all instances.
Thanks for responding so promptly – and, again, for your excellent guide!
Hi Guido,
I am reading your formatting document and using Textmate. Where is this following function? “Convert Selection to Entities excluding Tags” . I can’t find it?
Thanks
In the “Bundles->HTML->Entities” menu.
Alternatively simply type “entities” in the Help box and you will see it listed there.
I am wondering if I need to use the entity codes for some of the usual ASCII symbols like @ and \
All I can find for them is the numeric codes which you have suggested against.
Also, I’m not sure if this is the best section to ask this question in, but how do you go about hyperlinking text in HTML?
Thanks for the amazing guide!
No, symbols like @ and / do not need to be encoded as entities. They are part of the standard ASCII code set.
Linking is done the same way as in webpage. Use <a href=”http://URL_you_want_to_link_to”>This is a link to link to webpages, or use anchors via <a id=”ThisIsAnAnchor”> inside your text to link to.
Wondering if you could possibly add to your tutorial of the proper way to set up an eBook, what I mean by this is sections like Cover, Title Page, Copyright Page, Dedication Page, Table of Contents, Prologue, etc. and how the HTML structure would be set up for each of these.
Guido,
thanks for the great guide. Question for you. I’m publishing a lengthy text in Spanish. When I first published this online, to avoid having to use html escape codes for every single word, I simply declared the text type as utf-8 instead of ASCII. How well do e-readers support utf-8 and unicode? What’s your eperience?
UTF-8 is fully supported on eBook readers. In fact, it is the only encoding you should use for eBooks. However, that does not solve your problem that all special characters need to be converted into named entities, because UTF-8 on one device is not that same as UTF-8 on another device. Only named entities will circumvent those incompatibilities.
Guido – thank you so much for all your patient work here, it is a brilliant resource for html/e-book newcomers. I have a very quick question as TextWrangler is threatening to wrangle me in for good or I could just be overthinking, but is the entity for right-hand single curly quotes ’ also used to replace the ‘ in words such as don’t, wasn’t, didn’t, hasn’t?? Or are single curly quotes only utilised in phrases such as – known as ‘the king of kids’.
I was travelling along OK until the find/replace asked me this and, well, I am sure it is a simple answer… Thank you, Mel.
Yes, that is correct. The ’ entity is also used for apostrophes.
This is a GREAT tutorial series Guido. Thanks for posting it!
I do have a possibly dumb question. If our goal is to wind up with the source code (HTML) why use a word processor at all when writing the original document?
Wouldn’t it be more straightforward to just create it in Dreamweaver, Frontpage or the HTML editor of choice from the get-go, then clean up the code right there in the same application?
Thanks for all the help…. Jerry
I do not think Dreamweaver is at all suitable for writing projects. Not only are they not “writing” software. On top of it, they are overkill in the HTML department for the most part, and it iwll be hard to teach them to use a very limited, stripped down subset of HTML and CSS. To me it is just a matter of using the proper software for the job for best results. I, for example, use Scrivener for my writing, because it is a writing tool crafted specifically to suit writers. But sure, your mileage may vary.
Guido,
I’ve already converted one book using your guide and it worked perfectly. HOWEVER, I’m working on another (a short story), originally written in Rich Text Format (as the first book was), and once I do all the search and replacing in Word and bring the file into an editor (I use Komodo – which worked just fine the first time around), when I paste the file into the editor, instead of getting one continuous line, it appears to be formatted, with paragraph breaks, etc.
You stated: “Once you got over the shock that all formatting is lost, you may also notice that every paragraph of your original text is now in one single, long line. (If that is not the case, you should adjust the line width of the editor to its maximal possible length through the Options settings.)”
I have looked through Komodo and cannot find a setting to fix this. I even downloaded Text Mate (the same thing happened) and I cannot find how to adjust the line width in Text Mate either… I’m now stuck at this point and don’t know how to proceed.
This process went so smoothly the first time and it’s crazy frustrating to get stuck in such a silly spot like this… seems like this should be an easy fix but I can’t figure it out.
HELP!!
This sounds as if your Word file is already screwed up and has hard line breaks.
So how do I resolve that?
I can’t be sure what is going on without seeing the document, but as I said before, make sure your Word document is in order. Check every line to make sure there are no hard line breaks.
I was able to get this all resolved and complete the book. Viewed it in a Kindle app for my Mac and it looks awesome. Thanks for the help and these columns.
Guido says “If you mean replacing regular quotes to turn them into curly quotes, I don’t think any programming editor can do that. It requires some logic to identify the opening and closing quotes as they require different replacements. Word processors usually have that logic when “smart quotes” are turned on, but not programming editors.
If you mean by replacing, replacing the curly quotes with their respective entity values, you can do that in a quick two-step search and replace. Simply search and replace all occurrences of “ with the entity &ldquot; and then replacing all occurrences of ” with the entity &rdquot;”
Actually, Guido, your editor, TextMate, will allow you to replace ” and ‘ with the curly versions using a recursive regular expression that matches opening quotes with closing ones.
Guido,
Just use the following regular expression in TextMate to replace all ” with the appropriate curly quotes.
Find: “(?=[^>]*<(?!!ENTITY))((?[^”<']|]+[^>]*/>|<(?[^/ >]+)[^>]*>(?)(?[^”<']|]+[^>]*/>|”\g*”|<(?[^/ >]+)[^>]*>(?)\g*</\k>|'(?[^”<']|]+[^>]*/>|”\g*”|<(?[^/ >]+)[^>]*>(?)\g*</\k>)*’)*</\k>|’\g*’)*)”
Replace: “$1”
Guido,
I forgot to use on the last post. Here is the correct regex.
Find: “(?=[^>]*<(?!!ENTITY))((?[^”<']|]+[^>]*/>|<(?[^/ >]+)[^>]*>(?)(?[^”<']|]+[^>]*/>|”\g*”|<(?[^/ >]+)[^>]*>(?)\g*</\k>|'(?[^”<']|]+[^>]*/>|”\g*”|<(?[^/ >]+)[^>]*>(?)\g*</\k>)*’)*</\k>|’\g*’)*)”
Replace: “$1”
Very cool. I will have to try this out. Thanks.
Guido,
Let me try this again.
Find: “(?=[^>]*<(?!!ENTITY))((?<double>[^”<‘]|<[^/ >]+[^>]*/>|<(?<tagname>[^/ >]+)[^>]*>(?<!/>)(?<html>[^"<']|<[^/ >]+[^>]*/>|"\g<double>*"|<(?<tagname>[^/ >]+)[^>]*>(?<!/>)\g<html>*</\k<tagname+0>>|'(?<single>[^"<']|<[^/ >]+[^>]*/>|"\g<double>*"|<(?<tagname>[^/ >]+)[^>]*>(?<!/>)\g<html>*</\k<tagname+0>>)*')*</\k<tagname+0>>|'\g<single>*')*)"
Replace: “$1”
For some reason, some spaces were displayed as many spaces. Let’s try it again.
Find: “(?=[^>]*<(?!!ENTITY))((?<double>[^”<‘]|<[^/ >]+[^>]*/>|<(?<tagname>[^/ >]+)[^>]*>(?<!/>)(?<html>[^"<']|<[^/ >]+[^>]*/>|"\g<double>*"|<(?<tagname>[^/ >]+)[^>]*>(?<!/>)\g<html>*</\k<tagname+0>>|'(?<single>[^"<']|<[^/ >]+[^>]*/>|"\g<double>*"|<(?<tagname>[^/ >]+)[^>]*>(?<!/>)\g<html>*</\k<tagname+0>>)*')*</\k<tagname+0>>|'\g<single>*')*)"
Replace: “$1”
Well, I guess this site doesn’t support . Let’s try this again.
Find: “(?=[^>]*<(?!!ENTITY))((?<double>[^”<‘]|<[^/ >]+[^>]*/>|<(?<tagname>[^/ >]+)[^>]*>(?<!/>)(?<html>[^"<']|<[^/ >]+[^>]*/>|"\g<double>*"|<(?<tagname>[^/ >]+)[^>]*>(?<!/>)\g<html>*</\k<tagname+0>>|'(?<single>[^"<']|<[^/ >]+[^>]*/>|"\g<double>*"|<(?<tagname>[^/ >]+)[^>]*>(?<!/>)\g<html>*</\k<tagname+0>>)*')*</\k<tagname+0>>|'\g<single>*')*)"
Replace: “$1”
Hi Guido,
One thing to be careful of. If you have continuous italics on more than one line, Kindle appears to cancel the italics after the closing p tag at the end of the first line.
So, you can open the file in a browser and all lines are italic but in Kindle, only the first line is italic even though the italic tag hasn’t been closed.
Any ideas on how to prevent this?
thx
Italics should never go across paragraphs. Always start the italics inside the paragraph and end them before the closing of the paragraph. Like this…
<p><i>Here goes your text.</i></p>
Always make sure you maintain the order in which you open and close tags. If you close the </p> tag while there is still an active <i> tag, your code is not valid XHTML. Web browsers will usually ignore this kind of mistake and gloss over it but strict XHTML implementations, such as eBooks and other devices will reject the code as erroneous – and correctly so.
Thanks Guido, you are right. But the issue is the use of the Ctrl-i to search and replace italics in Word BEFORE pasting into TextMate or Notepad++. If you did not author the book, (or even if you did and weren’t super careful about how you italicized) then you may well get the i tag starting on one line and ending on a subsequent line. When you run your regular expression to add the p tags to each line in the bare TextMate text you will then get the situation I describe. I think people who follow your method (and it is a great method) need to be aware of this. If you can think of a regex to mitigate this please post it.
Just a quick follow up to my last post.
I just tried a test running your Ctrl-i search & replace italics in Word. I could not format the italicized text in such a way to avoid this problem. If Word has several italicized paragraphs in succession, your search and replace will insert the i tag at the start of paragraph 1 and place the closing /i tag at the end of the last paragraph. It will not start and close the i tag for each paragraph. If anyone has more than one italicized paragraph in succession the second paragraph will show as normal text.
Yes, this is something you will have to do by hand. From my experience, long, multi-paragraph passages of italic text are rare in novels, though, so it’s not that bad a problem, typically.
I just formatted a book full of consecutive italicized paragraphs. Two characters were communicating telepathically and the author had italicized that dialog. It would have been useful to check for the existence of consecutive italicized paragraphs before running the command to add the p tags in Notepad++. An expression could search for instances of the i tag at start of line with no corresponding closing i tag. I did have a similar expression for checking the existence of closing quotes but can no longer find it – took me hours to figure that it out – I’m not good with regex. If anyone knows such an expression, I’d love to have it. I still think the Guido method is the best solution for formatting eBooks.
Following up from my other posts, here is an expression to check for missing </i> tags in a paragraph containing an <i> tag
<i>(?:(?!</i>).)*$
Also, you can tweak this expression to search for missing end quotes and such.
Very cool, Paul. I’ll have to try that out. This could be very valuable. Thanks.
Up-to-date information for anyone using Notepad++.
You must install the ‘HTML Tag’ plugin as described in a previous post. However, when I did this yesterday the plugin failed and threw up a message box about not being able to find HTMLTag-entities.ini. I’m using Windows 7 and I think it’s a permissions issue, but I don’t really care as long as it works.
I got a copy of HTMLTag-entities.ini from here: http://cloverhome.googlecode.com/svn-history/r15/Software/Notepad++/plugins/Config/HTMLTag-entities.ini.
I put this in the location specified by the error message, told Windows 7 that yes, I want to run as admin, and HTML Tag then worked.
A further tip: you don’t want HTML Tag to change your (‘less than’ and ‘greater than’) into their corresponding HTML entities (at least, I don’t). To prevent this, modify your HTMLTag-entities.ini file. Comment out the lines for these by putting a semi-colon at the beginning of the line. They are:
‘lt=60’
‘gt=62’
Thanks Guido, this is amazing stuff!
Excellent series of posts. I’m glad you went into so much detail.
Sorry, I should’ve known that I could use tags in my comment above. You can delete that. This is the new post. I changed the some tag symbols to braces so it wouldn’t convert them into html tags.
Guido,
First off, thanks for answering a previous question I had the other day.
Now, onto a few more after doing a lot of trial and error on a huge document.
1) Your directions state: “In Word, for example, go to the search box and hit Ctrl-i to select italic”. I’ve done this on two different versions of Word on two different Apple computers. I’m still baffled at how this is working for you. Are you actually hitting the Ctrl and i buttons at the same time while your cursor is in the Find what field? (similar to how you would press CMD-C to copy). I feel like I’m missing something so basic because nothing happens when I do that. I have to go into the Advanced Find and Replace section, click on the Format drop down menu, and then select the Italic Font style. That ultimately works but you seem to be doing it a much easier way.
2) You state that we don’t want to fall into the same temptation to do this with bold text. So, if I have bolded words that are not things like chapter headers, are you suggesting that I have to just tag those manually? If so, should I use the <strong> tag or use some sort of css style?
3) Lastly, I just want to confirm this. For chapter headers, you suggest that those are done manually, correct? You suggest we use this code to set the style:
p.chapter { text-indent: 1.5em; font-weight: bold; font-size: 2em; }
But, I assume then we have to go to each chapter header and use the following code:
<p class=”chapter”>Chapter 1</p>
Am I understanding that correctly? My book has about 25 chapters so it’s just a bunch of copy/paste but obviously, it does bring in some room for error to do it 25 unique times.
4) On a non-coding topic, my understanding is that each version of a digital book (as well as a hardcopy) needs its own ISBN number. On the copyright page, is it smart to include the ISBN number or do people just include it in the meta-data? The reason I ask is because it seems that if one were to include it in the book, you would need to send multiple versions into Calibre, each version having a diff ISBN in it.
5) Similar to #5, Amazon does not require an ISBN since it applies it’s own ASIN number. Is it smart to have a real ISBN number anyway?
Thanks again for all your help. I’ve got a book that has a lot of extra stuff, outside of the story, which has a lot of bolding and italics and tons of quotes.
Paul
Paul,
ad 1) This shortcut may not work on the Mac. I found Ctrl-i doesn’t even work in Windows properly, depending on the version of Word you’re using.
ad 2) If you have text that is just bold, yes, just wrap it with <b> or <strong> tags.
ad 3) You can automate this with a search and replace with a Regular Expression and that way minimize errors.
ad 4) One ISBN is fine for all your eBook editions. You do not have to have different ones for each version. Most of the time I don’t even include the ISBN in the actual eBook at all. I only add it when listing the book on a distribution portal. That way I don’t have to keep track of versions or anything.
ad 5) Same goes for Amazon. No ISBN.
Guido,
Thanks for your help. If I missed it in the article, is there a suggested way to do #3 with a search/replace using a regular expression?
Also, I’ve read so many places about needing a separate ISBN for different formats (although again, one does not need one for Amazon or even B&N apparently). I’m going to keep digging and I’m definitely not trying to be argumentative. It seems quite confusing.
Paul
Well, I am living proof that DO NOT need separate ISBNs. I have one ISBN for each of my eBooks, regardless of the format. You have to understand that ultimately YOU are in charge of your ISBNs, and not Amazon or B&N.
Hi Guido,
Thank you so much for this helpful guide. The only thing I can’t get to work is the Table of Contents. I’m using an image for the chapters so there is no actual chapter title, and I tried to use the hidden visibility code but all the chapters show up as unnamed. Am I missing something obvious?
I’m using this code:
p.centered
{
text-indent: 0em;
font-weight: bold;
font-size: 1em;
text-align: center;
margin-top:2em;
margin-bottom:2em;
}
span.centered
{
text-indent: 0em;
text-align: center;
margin-top:5em;
margin-bottom:2em;
}
p.chapter
{
text-indent: 1.5em;
font-weight: bold;
font-size: 1.5em;
page-break-before: always;
margin-top:5em;
margin-bottom:2em;
}
p.TOConly
{
visibility:hidden;
display: none;
}
and then this for each chapter heading:
Chapter 1
and I changed the structure detection and the Table of Contents level 1 setting to:
//h:p[re:test(@class, “chapter”, “i”) or re:test(@class, “TOConly”, “i”) ]
Do I have it all wrong? I just can’t figure it out.
Thanks for any help!
Jenifer
Thanks so much for this guide. I published my first ebook on Amazon converting from a work doc, and I am disappointed with it. Luckily, I have some experience with html, so this is not too confusing for me. I’m working on formatting my second book now, and this is exactly what I needed.
I really appreciate your taking the time to do this!
Guido, I made a graphic for my ebook, black with a white background. When I viewed it in the Kindle ap on my Android device, the white wasn’t the seame background as the book, and it looked like a postage stamp. Any way to put in an image whose background always matches the Kindle background?
Morris Graham
For the most part you just need to make it true white and it will blend with the Kindle’s standard background.
However, when you switch the Kindle theme to Night or inverted, it will not work correctly, leaving a white block around you image. The only way to prevent that would be using the transparency of a 24 bit PNG file, but sadly most Kindles do not support that. They support 24-bot PNG but not the transparency. You could use 8-bit PNG files with transprency. That works, but since it is anti-aliased towards a fixed background color, once again, in inverted or Night modes, this will look a bit strange also, leaving some artifacts around the edges.
Thanx
Thank you. I have a bookcover question. There seems to be a lot of opinion about what size/resolution, etc… If I understand this right, Kindle requires that you build a library cover that they can display on their website, and also a cover for inside the book. They will also resize a thumbnail for their website. What are the ideal Library and internal book cover dimensions in dpi, aspect ration, and pixel dimensions…etc. Also, I would appreciate it if there is anything else I have missed asking, feel free. I am also building a cover for create space, so I would possibly like to use the front cover from it for the libray image. The front cover on my create space book will be 6×9″, and they request minimum of 300dpi.
Thanx, Morris
Hi Guido,
Thank you so very much for your guide. I am converting a MS Word doc to e book and I think I am with you so far. I know almost nothing about HTML so am very new here. I’ve gotten to your section: Dealing with special characters the right way and found the command in TextMate Convert Selection to Entities excluding Tags In the “Bundles->HTML->Entities” menu, and I have your suggestions for replacements, but I don’t know how to enter them. Can you provide specific instructions as you did with the find and replace step? Or can you send me in the direction of basic tutorials that might help. I’d really like to do this myself as you’ve built such a good case for doing so. Thanks, Lyneah
All you do is, select the entire body of your eBook from the <body> to the </body> tag and then select the “Convert selection to entities…”
ps instead of quotes I have “What a great day!â€
Thank you Guido. You are so patient. It’s like speaking a foreign language, the cognates are the hardest because you are looking for something more difficult. I have done that and will forge on with your instructions. Thanks again. I look forward to downloading some of your books.
On second question, from the what to the tag?
Sorry, that was meant to be from the <body> to the </body> tag.
Thanks. I need to perhaps redo that above step. Back to reading your blog again. OK, I’ve rerun the conversion before adding the paragraph markers and that took care of the anomalies I was seeing previously in the browser window. Now all I have that is not yet right is the italics. Here is what I have: “Ghost ? Dead?” I suddenly realized
Is there a short way to fix this at this point or do I have to start over back in MS Word (I totally agree with you about Word!) to somehow redo the italics markings? Thank you again for your help.
Hi Guido, Happy 4th. I have made progress. I had to redo all the italics tags because they were not showing up properly in some browser windows. The only other thing now is the spacing between paragraphs. Does that get adjusted in Calibre or do I need to do it in TextMate? If in TextMate can you enlighten me on what part of the initial code defines the spaces between paragraphs? Thanks, Lyneah
Lyneah, paragraph spacing is determined in your <p> styling. Add an entry called margin-bottom: 1em; for example and your paragraphs should show some spacing.
Thanks Guido, I may be dense on this one. This is what I have at the beginning. I have changed the value of the margin-bottom in several ways and I still have a line between every paragraph. I’d rather have no lines between paragraphs.
html, body, div, h1, h2, h3, h4, h5, h6, ul, ol, dl, li, dt, dd, p, pre, table, th, td, tr { margin: 0; padding: 0em; }
p
{
text-indent: 1.5em;
margin-bottom: 1em;
margin-left: 0.1cm;
}
p.chapter
{
text-indent: 1.5em;
font-weight: bold;
font-size: 2em;
}
p.center
{
text-indent: 0em;
text-align: center;
}
span.center
{
text-indent: 0em;
text-align: center;
<p class="” style=”display:none”>
<p class="” style=”display:none”>
With margin-bottom at 0 em it still gives me a line after each paragraph. I have indents so I don’t need to use up all that extra space.
Hello Guido, Thank you so much for these posts/ I do hope and pray you are still replying to questions.
This is my first attempt at doing any html codes. I have been following your guide step by step and up until now it has all worked like a charm.
After I saved the html file I clicked on it to view and everything is formatted beautifully except for the &ldquot; and the &rdquot; it shows in the manuscript. (It isn’t supposed to show in the saved html file right?) I have tried adding a space in front and one behind each as well as removing the spaces.
Can you please tell me what I am doing wrong.
They are called “ and ” It appears you have misspelled them with a ‘t’ at the end.
Hello Guido and thanks for your postings. I have a question re: your recommendation to always named enttities over number entities. The official HTML w3schools says this:
“The advantage of using an entity name, instead of a number, is that the name is easier to remember. However, the disadvantage is that browsers may not support all entity names (the support for entity numbers is very good).”
While I love w3schools, this comment is simply not accurate. Numeric entities cause all kinds of problems. It is correct that they are well supported. The problem is that they are not uniformly supported, meaning, a numeric entity means one thing on one platform, and another thing on a different one. Just make an HTML file with various numeric entities and try to display the file on Windows and then on a Mac. Most likely you’ll be getting a lot of garbage even with some of the most basic and commonly used spacial characters. The same goes for eBook readers.
While there are a few named entities that are not properly supported by some browsers or eBooks, those are typically very obscure ones – you don’t want to go there with an eBook, anyway. From my experience of formatting well over 500 eBooks, using named entities will give you what you need, while numeric entities will give you headaches, so the choice and recommendation for me is very simple.
Thanks, Guido, for updating this so faithfully! Something I noticed while using Word’s ‘replace’ to change all italics out (Find: Ctrl+I) into bracketed passages (^&): The find/replace worked great, but the then-bracketed phrases PLUS the bracket commands surrounding them were all in italics. I assume the words and brackets should ultimately be styled without italics (on Word’s screen and printouts), so I highlighted my symbols in the ‘replace’ field and hit Ctrl+i twice which produced ‘Font: Not Italic’ under the field. This removed the Word styling while adding the html tags to each phrase. How important was this to do, and is it right to do it? Also, this may have been mentioned but may be helpful: I find that with styles it’s best to change them to commands one incident at a time, since I didn’t always turn off the styles right away before hitting space or return when composing the document. ‘Finding next’ and replacing them one at a time (instead of replace all) allows me to clean this up first so the brackets are right where they need to be, tight against the desired-styled content.
Regarding removing Word’s italic’s style while adding the formatting, in my comment above, it occurs to me now that it’s probably unnecessary, since I suspect moving the text to any editor will remove the Word styling.
Hi Guido,
First, I want to thank you for posting this information for all those folk like me who are new at Self-Pubbing and HTML gig! You are a rockstar…or perhaps litstar?
My question concerns cover art. I’ve found a great artist who will do an original artwork of a scene from my novel for a great price. However, we have questions as to what size the original artwork itself should be, as well as correct sizing for Kindle. As to the latter the 600×800 and 72dpi rule seems to be the standard. But the artwork itself? What are your recommendations?
FYI, I will be using your guide for html formatting from start to finish to transform my ms to Amazon/Kindle friendly ebook ready work and have already pointed your site out to friends looking for good help in self pub.
Again, thank you!
Kate Dancey (aka C.K. Garner)
At this time I would make a cover no smaller than 1024 pixels wide. Since the current generation of iPads has a resolution of 2048×1536 pixels, that is the resolution I would go for if you want to stay on the high end.
Hi
Thank you very much for the informative series. I converted one of my friend’s books. The only thing I missed was the quotes issue. After reading the comments here I have seen where I went wrong. I am ready to convert my four books into ebooks this holiday, thanks to you. forever grateful
Do you know of JEdit has a similar function to ‘“Convert Selection to Entities excluding Tags” to change all special characters to HTML at once?
Thank you.
Yes, JEdit should have this functionality as part of their XML extension (http://plugins.jedit.org/plugins/?XML) I am not all that familiar with JEdit, so I am not sure exactly how to access it, but it should be there somewhere.
Thanks, Guido. I downloaded the plugin, but can’t find where it is. I may just go ahead and purchase TextMate. Thanks for helping all of us.
Hi Guido,
thanks for putting together a great guide! I followed your recommendation to find and replace all the curly quotes, em dashes etc in my manuscript in Microsoft Word. Then I entered a chapter in the program editor (JEdit). Everything worked fine until I saved the chapter as an html file and opened it in a web browser. (I had to use notepad in order to save it as an HTML file.) All the curly quotes come up as bold question marks. What do you think I might have done wrong?
Sounds like you did not convert them named entities.
Thanks, Guido! You’re right!
Hey Guido.
another quick question (should be last): I used the plug-in feature in Notepad++ to automatically convert curly quotes, ellipses etc to named entities. However, now all the italicized words—which I changed when I was in my word processor and then pasted in entire document into Notepad—show up as bla, bla, bla. In other words, it seems like applying the automated way to convert to named entities wiped out the formatting of the italicized words. (They looked fine before applied the conversion.) I can fix it by manually applying the after conversion, but it seems unnecessary. Did I do something wrong that wiped out the italics formatting? Also, does it matter if you use or or are those interchangeable?
Thanks again for writing such a thorough guide.
Okay, I see here when I apply the html signs it coverts it. In the place where it says bla, bla, bla I wanted to show you that the actual mark-ups are visible, not change the “bla, bla, bla.” I wrapped the bla’c with <i'". I intentionally added that quotation mark so that it would show. Also, have no idea why the end sentence in my previous comment is italicized.
Sorry to be such a pain in the butt, but now I’m worried that the (again, am adding the quotation mark so you can see what I’m talking about) will show up in some Ereader if I add them manually afterward since they’re not converted to named entities. Also, since I have to add all of them manually in the Notepad anyway, why would I add them when I have the document in my word processor? It’s seems like an unnecessary step.
Hi Guido, great guide. I’m using a programming editor called Notepad++ and, for some reason, the search tool isn’t picking up any quotation marks. I’ve been through the word document and replaced each one (as advised) and wondered if it might be something simple I’m doing wrong – are you able to advise?
Hi, I spent 4 hours doing all this up to part VI, very carefully doing all of the search and replace actions on my document setup in Notepad 6.5.5, which has very sophisticated search & replace. I saved it as an HTML doc and double-clicked on it, and it came up on the browser as a document like notepad, one solid mass of text, no paragraph breaks or page breaks, and with many strange symbols. It was a total disaster after 4 hours of patiently doing everything you described. I’m rather pissed at wasting my time. At first I entered the code for the dash without the brackets , and it just replaced all the long dashes with the letters of the code. I reversed out of that by replacing all those codes without the brackets, but I was so nervous I used the [] brackets by mistake instead of . So I changed it again to the right brackets , and then resumed and did it exactly as you described, and got the result I described, a mass of text. I was so hoping I’d finally found a clear, consistent, trustworthy set of instructions. It’s incredibly disappointing! …
I am sorry to hear that, of course, because as you may know, so many authors have found these instructions incredibly helpful. Feel free to email me your HTML file and I’ll give it a quick look to see what’s going on there.
Hi again Guido. Thanks, that would be great. I thought I would just proceed to Part VII, and hope the problem clarified itself later on, but it would be much better to clear up the mistake I’ve made before going on. I’ve looked for your email address on your site, but I cannot see it. Where should I send my HTML document to?
Thanks
I forgot to say, I cleared up one aspect of it so the browser text now appears in correct paragraphs, by using your 2nd replacement for the ^(.+)$ search. But the replacements for …, single & double quotation marks, and long dash, when I look at the text in browser mode the code for all that appears on the screen.
The email is right on this page – http://guidohenkel.com/about/
I just wanted to let everyone know, that I have just published a book called “Zen of eBook Formatting” that is now available. It covers the aspects from this tutorial in a lot more detail and also adds a hole lot of additional info, details and advanced techniques to the mix. Here is a link with a bit more info, including a look at the Table of Contents of the book.
http://guidohenkel.com/2014/05/zen-of-ebook-formatting-is-now-available/
Hi Guido,
I have used your guide many times to format ebooks with great success. I am using TextMate on a Mac. Suddenly I am running into a dead end where Find: ^(.+$ and Replace with: $1 does absolutely nothing. Mysteriously, I am getting a message that says regexp: end. Regular expressions are enabled.
Has anyone else run into this problem?
I have not run into this particular problem, but the search term should be ^(.+$), shouldn’t it? You are missing the closing parenthesis which would make it a valid term.
Solved it, Guido! You’re the best. I can’t believe I missed something that obvious! Thank you.
Guido,
I tried to post this regex two years ago, but couldn’t get it to format correctly. I am going to try again.
The following regex will find paired double quotes(“) and turn them into curly quotes.
Find: “(?=[^>]*<)((?<double>([^”<‘]|<[^ />]+[^>]*/>|<(?<tagname>[^ />]++)[^>]*>(?<html>([^”<‘]|”\g<double>”|<[^ />]+[^>]*/>|<(?<tagname>[^ />]++)[^>]*>\g<html></\k<tagname+0>>|'(?<single>([^”<‘]|”\g<double>”|<[^ />]+[^>]*/>|<(?<tagname>[^ />]++)[^>]*>\g<html></\k<tagname+0>>)*+)’)*+)</\k<tagname+0>>|’\g<single>’)*+))”
Replace: “$1”
A double quote string can be nested inside a single quote string that is itself nested inside a double quote string. In order that this regex can find the nested double quote strings, all apostrophes must be replaced with ' so that the only remaining ‘ characters are actual single quotes
Guido,
The "s were automatically changed to “s, the ' were automatically changed to ‘ and the spaces were made into huge gaps so I’ll try again.
The following regex will find paired double quotes(") and turn them into curly quotes.
Find: "(?=[^>]*<)((?<double>([^"<']|<[^ />]+[^>]*/>|<(?<tagname>[^ />]++)[^>]*>(?<html>([^"<']|"\g<double>"|<[^ />]+[^>]*/>|<(?<tagname>[^ />]++)[^>]*>\g<html></\k<tagname+0>>|'(?<single>([^"<']|"\g<double>"|<[^ />]+[^>]*/>|<(?<tagname>[^ />]++)[^>]*>\g<html></\k<tagname+0>>)*+)')*+)</\k<tagname+0>>|'\g<single>')*+))"
Replace: “$1”
A double quote string can be nested inside a single quote string that is itself nested inside a double quote string. In order that this regex can find the nested double quote strings, all apostrophes must be replaced with ' so that the only remaining ‘ characters are actual single quotes
This regex works in TextMate
Guido,
You can copy/paste the regex in the above post into TextMate and it should work. Let me know if it does.
By the way, the paragraph after the regex should say to replace apostrophes with ' so that the only remaining ' are actual single quotes.
After running the regex, you can change your ' entities to ‘ if you wish.
Sorry, I meant to say change ' entities to ’
By the way, this regex only works on html files, not regular text files. The regex requires the < and > to represent html tags.
Guido,
Also, the regex only works if you use Replace All. For some reason, it doesn’t work when you use Replace or Replace & Find.
(TextMate version 1.5.11)
Dear Guido,
first of all, thank you so much for this amazing guide! I’ve just bought your book, too, and am working my way through right now for more details on how to get everything just right.
I’m having an odd problem with em-dashes, though – when I replace them with —, they show up as — (three separate dashes) both in the html preview version in my browser, and in the converted epub (so far viewed with Kindle for PC and Moonreader on my Samsung pad).
Incidentally, the same thing happens when I look at your “Zen” book in epub format (I’ve converted it from the weird Amazon format with Calibre because my tablet won’t handle azw).
I’ve taken the trouble to look at the code in an epub ebook that correctly displays em-dashes for me, and it doesn’t have entities at all, but just uses curly quotes, em-dashes and so forth in the code.
This doesn’t seem to happen to everyone, so… what am I doing wrong? Is it a Calibre setting…?
Thank you very much!
Sylvia
Errr. In the second paragraph, it should read “when I replace them with & m d a s h ; (the entity for em-dashes), they show up as – – – (three separate dashes, though without spaces).
The form changed everything to proper em-dashes and confused the issue. 😉
I am not sure how this would happen. I see no rational explanation why an — entity would suddenly be displayed as three individual dashes—unless the Samsung is doing something really wonky. Can you send me the source code, perhaps, so I can take a look?
I will send it per email – thank you very much!
Hi Guido –
Thank you so much for doing this series – I am also going to be getting your book since it looks like I am going to be doing a bit of this. The first round I have to do is a series of ebooks and I’m just beginning to work through it.
Couple of questions though –
1. Search and replace of italics on mac with word 2011 will not work with the ctrl-i that you mentioned but the guy above (sorry I forget your name) talked about the workaround of using the find/replace with the format font commands and that seems to work but what I end up with is this for example: Achievable Goals
with the closing code on the next line. Is that correct or do I have to manually go through and move it up after the italicized text?
2. Am I reading it correctly that the only fonts available in readers are the 3 you listed above? These word files are all in Arial so what will happen when I create the ebook. Do I need to change the fonts to one of the above before I start?
3. If I read you correctly, Calibre will create the TOC so I don’t have to do that in Word, correct?
4. What about pagination in word – do I clear that out before sending it to textmate?
5. Is it appropriate to add page headers to the word doc? This is a sort of textbook series and I was thinking of using headers with the unit number and title – or will that just be too messy?
6. Then what about covers – what size do they need to be for calibre?
I’m sure I will have more questions as I work through this but I’m so glad to have found you – it is saving me from wasting a lot of time and not being able to provide a good product.
Sorry – I copy/pasted the italics from the doc and they didn’t show so here is what is showing:
Achievable Goals
next line of text. . . .
Well, this might end up a duplicate post but the one I just send is not showing.
The result from using the workaround from the above post ends up looking like this:
Achievable Goals
continuing text
Deborah,
Sorry for the sales pitch, but it seems appropriate in this case, because with all these incredibly specific questions, I would recommend you take a closer look at my book “Zen of eBook Formatting.”
It is an updated and hugely expanded look at the creation of eBooks, based on this blog tutorial, but it covers all the questions you raised, and also covers a large number of additional topics.
Thanks Guido – I’m getting it today and I hope I can ask any questions I might have once I start going through it.
Hi! I’m a little confused about the html entities. Where do I change them at? Search and Replace? And how do they go, like this … ?
Thank You Guido! 🙂
Hi Guido! Sorry for the posts from before, but I’ve found the solution! 🙂 I looked more carefully over the comments here and thanks to a Timothy Clayton, I’ve found the solution. I did have to do a find and replace for the italics, but it worked!
Cheers! 🙂
Hello Guido, love your series. Thank you so much. It’s going well– except I have some Turkish letters (ş, ğ, ı) for which there don’t seem to be any codes (ex Ooum:) for except for numeric codes (#105;). Is there some way to do them that I can’t figure out? Thank you so much. J.
Hi Jan, for those charcaters you will have to go with numeric entities because they are not defined in the set of named entities.
Thank you for clearing that up. I have three long novels set in Turkey, so this is a hot tip 🙂
If you haven’t purchased the book yet, make sure to do so now. The new version has been adapted to current developments and expands on various subjects to clarify and to accommodate new developments in eBook devices.
Click here to grab the book on Amazon!
I for some reason can’t figure out how to save my file to a .html file from the jEdit program, how is this done?
Just go to File->Save as” and then type in the name, ending with an HTML extension, like “test.html”
Okay, last question of the day.
I’ve indicated telepathy by indicating them with forward-slashes, /Like so./
I don’t picture that will play well with HTML; should I find-replace using the named entity ⁄ (fraction slash)? Or go ahead and find-replace with / ; ? Or are they safe inside their P tags?
Thanks!
Sorry if this double-posts.
In my scifi novel, I indicate psychic text using forward slashes, /like so./
I don’t picture that’ll play well with the HTML tags. Should I find-replace with ⁄ (& frasl ;), use & #47 ; (which you advise against), or are my little slashes safe inside their P tags?
MANY THANKS
Those slashes are perfectly safe within the paragraphs and you do not need to use any special characters or entities for it.
Hi Guido,
Many thanks for taking the time in writing this guide.
I would like to know if, in jEdit, there is an equivalent for the function called “Convert Selection to Entities excluding Tags”
Thank you
I honestly do not recall. It’s been years since I last looked at jEdit, I’m afraid.
Thank you anyway. I am really grateful for you writing this guide.
All the best,
Dan