
Zen of Defensive Programming: One operation per line
After discussing the evils of ternary operators in my last installment, let’s extrapolate a little from that last example. Just as a reminder, I had exploded a single line of code into a much more readable and maintainable code block. It is probably best expressed in a simple, single rule.
Only have one operation per line!
To me, this almost goes without saying. However, as I look at other people’s code, it reminds me again and again, just how blatantly programmers will abuse their languages if you let them. Meanwhile, seasoned programmers will instantly nod their heads in agreement with the rule because it is truly a no-brainer.
In the last installment, I already illustrated how breaking down a series of complex operations into individual steps can make code more readable. Today, let me show you some of the other benefits you will gain from it.
As a programmer, it is often tempting to pack a series of simple operations into a single expression.
size_t offset = ((yPos * 320) + xPos) * sizeof(RGB565);This seems innocent enough. It is a fairly short line of code. With a little bit of effort, you can probably figure out what it does. But therein lies the rub. You’re not supposed to figure it out. The code should tell you what it is doing without making you guess.
That aside, let’s explode the code and look at it again.
size_t lineOffset = yPos * 320;
size_t blockOffset = lineOffset + xPos;
size_t finalOffset = blockOffset * sizeof(RGB565);Instantly, we solved the mystery. You read the code, you know that it calculates the offset into a 2D pixel array. Moreover, you can very easily follow the steps that are necessary to correctly calculate that offset.
Debugging benefits
Aside from the improved readability of the code, the added benefit is that your code is much more debuggable. As you trace through these lines of code you can see exactly the result each calculation yields. Any mistake is going to be revealed very quickly. In addition, if you suspect any of the partial calculations to be the culprit of a defect, you can simply place a breakpoint on it, run the program and stop execution where it is needed.
Mixing in the different calculations in a single line of code does not give you that benefit. You won’t be able to see the intermediate results, only the values going in and whatever the final offset is. In a relatively simple calculation like this one, it may not seem like much of a benefit. If you ever got stuck on a crash bug, however, in a line that is so convoluted that you simply cannot figure out which term causes a segmentation fault, for example, you will very quickly appreciate the cleanliness and maintainability of the “One operation per line” rule.
It may result in more lines of source code, but if you think this is unnecessarily tedious, I guarantee, you will remember my words, the next time this particular kind of problem will cost you hours of needless debugging or will force you to rewrite your code and explode it anyway. You can avoid this problem so easily altogether. Just make “one-operation-per-line” a habit and stick with it.
Steve Maguire, the author of “Writing Solid Code,” calls this kind of cram-as-much-on-a-single-line-as-you-can mentality One-line-itis. It is a truly apt term for a problem that presents itself as a kind of programming disorder.
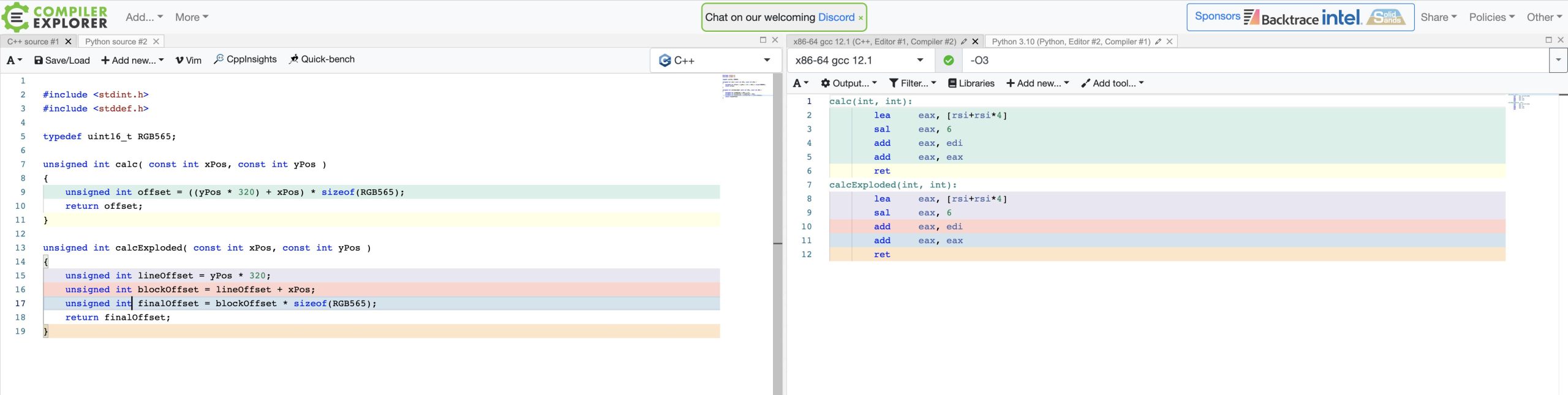
If you are afflicted by One-line-itis, be assured that you are not doing anyone a favor! Not yourself. Not your team members. Certainly not the poor soul who is debugging your code. Just to prove the point, here is the compiler output for both versions, showing that there is no difference in the generated code, so why obfuscate your code when it has no advantages?
Note: Do not mistake One-line-itis with compact programming, however. Some languages model certain constructs to be very concise and compact by design. Python’s list comprehensions are a perfect example of this. The intention here is to keep the entire operation in a single line. It is an actual language construct, however, and does not really imply language abuse. (Whether it’s a good language idiom or not is, perhaps, a discussion for another day.)
Apply liberally
Another instance where I see this kind of abuse very frequently is in loops. Let’s take a look at this code, for example.
int offset = 100;
// …some code
for ( int x=0, y=25; x<180 && somecondition; x++, y+=10, offset -= 2 )
{
// …do some terrible important stuff
}Notice the convoluted loop header, declaring and initializing multiple variables, checking conditions, and then incrementing numerous variables. All perfectly legal stuff, but is it good?
If we follow our defensive “One operation per line” rule, we could break down the code like this.
int y = 25;
for ( int x=0; x<180 && somecondition; x++ )
{
// …do some terribly important stuff
y += 10;
offset -= 2;
}As you can see, I am removing the clutter from the loop definition. I’m moving the iterative part to the loop body, leaving only one variable inside the loop definition. This adds clarity to the definition and makes the loop more understandable. Moving the increments to the body makes it easier to debug, allowing us to observe the values updating one step at a time.
Better yet, we can rewrite the loop like this and make it even clearer.
int x =0;
int y = 25;
while ( x<180 && somecondition )
{
// …do some terribly important stuff
x++;
y += 10;
offset -= 2;
}In this version, everything is laid bare entirely. The definition of all variables, the condition checks, as well as the iterative increments. And, do I need to really say it? To the compiler, it makes no difference. Even without any compiler optimization, the generated code is identical in all three versions.

Early Return vs. Single Return
This brings us to one of the great controversies in the programming community: Early Return vs. Single Return.
Let’s assume you have a function with a guard clause. You essentially have two options, on how to treat this. You do the guard check and if it fails, you instantly return. Alternatively, you do the check, and if it succeeds, you execute some code in the condition branch. The failed check will simply skip the code branch.
Perhaps it is easier to show this in code. This is an example of an early-return design.
int someCalculation( const int inVal )
{
if ( val < 0 )
{
return -1;
}
if ( someExternalConditionIsNotMet )
{
return 0;
}
…let’s assume there are some complex
…calculations and operations here that
…are really important
return someResult;
}By contrast, this is what a single-return design of the same function could look like.
int someCalculation( const int inVal )
{
int retVal = -1;
if ( val >= 0 )
{
retVal = 0;
if ( someExternalConditionIsMet )
{
…let’s assume there are some complex
…calculations and operations here that
…are really important
retVal = someResult;
}
}
return retVal;
}As you can see, the early-return version leaves the function as soon as it can in multiple locations. The second design nests the conditions, updates a return value as it goes along, and eventually leaves the function at one clearly defined point.
Occasionally, you will also see programmers go to even further lengths to “shorten” their source code and will make it look like this.
int someCalculation( const int inVal )
{
if ( val < 0 ) return -1;
if ( someExternalConditionIsNotMet ) return 0;
…let’s assume there are some complex
…calculations and operations here that
…are really important
return someResult;
}By now, you are, of course, well aware of all the issues arising from this code snippet and its violations of good coding practices. Missing braces, multiple operations in a single line, multiple return points. You do not want to be the author of this code because programmers are judged for their bad code. However, they are also judged for writing good code, and that is what you should be striving for.
The argument for early-return strategies is usually that single returns can result in deep code nesting, meaning your code moves further and further to the right and potentially off-screen. From my experience, that is typically not the case, particularly if you keep your functions small—as you should. That aside, however, I have never looked at nesting as anything bad. It is a way to properly illustrate dependencies and flow, which is extremely important in my opinion. Even at a glance, you can tell that, in order to execute, a piece of code has to meet several conditions. How is that ever a bad thing?
Use your screen real estate
With the available screen real estate we have available to us these days, the argument that nesting is problematic because it potentially pushes code off the screen is also naught. Just make your window wider or get a widescreen monitor if that is truly an issue for you. It’s not the 80s anymore where we could fit only 80 characters on a screen line.
Aside from the aesthetic differences, however, there are also very good technical reasons why you should avoid early returns.
If conditions change, early returns can easily hide the fact that a previous check already terminated the function. Your execution may never even get to the point you expect it to reach.
An even more important aspect comes into play if at some point during development you realize that you have to manipulate the return value for some reason. Let’s say you have to scale the return value or normalize it. If your function used an early return strategy, you now find that you have to locate every individual return statement and add the adjustment. Not only does this create unnecessary code overhead, but more importantly, it is prone to errors, because it is easy to overlook a return statement hidden somewhere in the folds of a function. The result of such an oversight can be fatal.
With a single return design, this cannot happen. All you have to do is add your normalization code just before the return and you’re done, well knowing that you caught all possible conditions. That, my friends, is code safety!
int someCalculation( const int inVal )
{
int retVal = -1;
if ( val >= 0 )
{
retVal = 0;
if ( someExternalConditionIsMet )
{
…let’s assume there are some complex
…calculations and operations here that
…are really important
retVal = someResult;
}
}
retVal = normalize( retVal );
return retVal;
}The benefits become even more obvious if you realize that you need to protect the code in your function with a mutex lock, for example, so it can run in a multi-threaded environment. In such a situation, an early return may result in a deadlock because of an unreleased lock. Once again, the single-return design makes it very easy to prevent this. There is a clear entry point and a single exit point, both of which can be firmly controlled. While scoped locks in C++17 allow you to work around this issue very elegantly, other languages and dialects often do not afford you that luxury, making it necessary to manually call the respective lock and corresponding unlock functions for each return.
The debate that shouldn’t be
As you can see, the Early Return vs. Single Return debate should not even be a conversation because the single-return design offers nothing but benefits. It will help you write better, more defensive code, whereas the early-return design offers only more spaghetti code and introduces unnecessary risks.
Zen of Defensive Programming
Part I • Part II • Part III • Part IV • Part V • Part VI • Part VII • Part VIII • Part IX

Thanks for stopping by. Preparing content such as the one you have just read takes time and effort to prepare. If you enjoyed it and are using a Brave browser, please feel free to leave a small tip as a sign of your support by clicking on the small BAT icon at the top of your browser window. Your tip is much appreciated and it encourages me to continue providing more content such as this.